The multi-institutional, large-scale project led by Jason Yik (Harvard), Vijay Janapa Reddi (Harvard), and Charlotte Frenkel (TU Delft) has been published in Nature Communications.
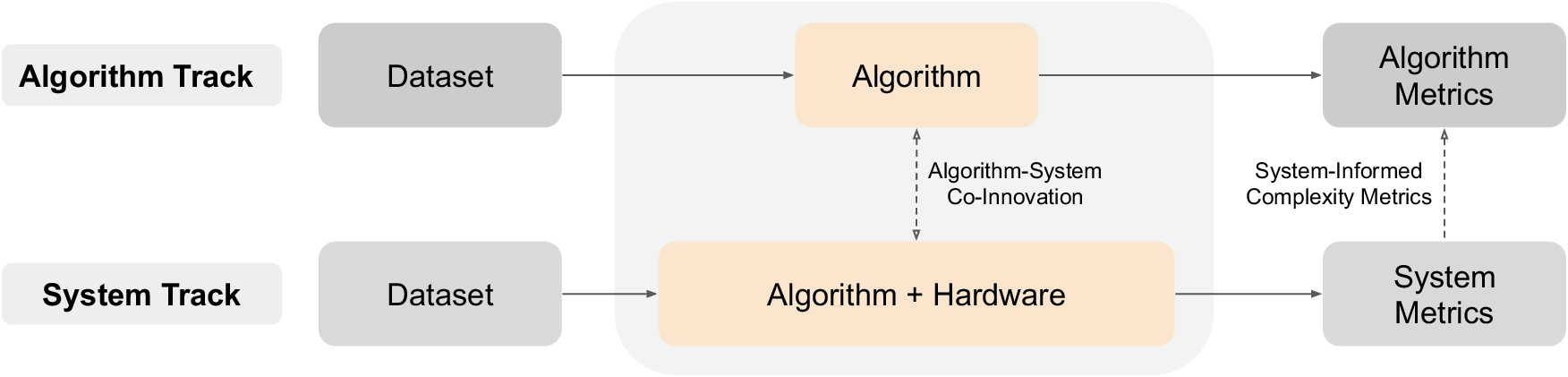
Abstract: Neuromorphic computing shows promise for advancing computing efficiency and capabilities of AI applications using brain-inspired principles. However, the neuromorphic research field currently lacks standardized benchmarks, making it difficult to accurately measure technological advancements, compare performance with conventional methods, and identify promising future research directions. This article presents NeuroBench, a benchmark framework for neuromorphic algorithms and systems, which is collaboratively designed from an open community of researchers across industry and academia. NeuroBench introduces a common set of tools and systematic methodology for inclusive benchmark measurement, delivering an objective reference framework for quantifying neuromorphic approaches in both hardware-independent and hardware-dependent settings. For latest project updates, visit the project website (neurobench.ai).