The next tutorial from UCSC’s Brain-Inspired Machine Learning class is by Ethan Mulle and Abhinandan Singh. The link is here.
They show how to train an SNN using the Forward-Forward Algorithm by Geoff Hinton.

The next tutorial from UCSC’s Brain-Inspired Machine Learning class is by Ethan Mulle and Abhinandan Singh. The link is here.
They show how to train an SNN using the Forward-Forward Algorithm by Geoff Hinton.
The cost of processing language models is insane. It is estimated that the computation demands of ChatGPT are >$100,000 p/day to serve billions of requests received.
Led by Rui-Jie Zhu, we have developed the first MatMul-free language model (VMM/MMM-free) to scale beyond billion-parameters. Our previous work with SpikeGPT tapped out at about 216M parameters, but our latest model has been able to go up to 2.7B parameters (only limited by compute). We’re pretty certain it can keep going.
We provide a GPU-optimized implementation that uses 61% less VRAM over an unoptimized implementation during training.
However, there are several operations in this model that GPUs aren’t yet fully optimized for, such as ternary operations. So Ethan Sifferman, Tyler Sheaves and Dustin R. built a custom FPGA implementation to really milk it, and we can reach human-reading throughput at 13W. A little less than the power consumed by the human brain.
Preprint: https://lnkd.in/gaWbg7ss
GitHub training code: https://lnkd.in/gKFzQs_z
Pre-trained models on HuggingFace: https://lnkd.in/gDXFjPdm

From the guy who built the first spiking language generation model, Rui-Jie Zhu has found a way to make spiking neural networks (SNNs) perform end-to-end autonomous vehicle control. This model takes a 6-camera input and integrates perception, prediction and planning together into a single model with approximately 75x less operations than ST-P3 at comparable performance.
Making SNNs push beyond toy datasets has been a tough time, but we’ve put a lot of effort into showing how to scale to challenging, real-world problems. The next step for this model is to push it into a closed-loop system. Deploying models like this on low-latency neuromorphic hardware can enable fast response times from sensor to control. This is necessary if we want to bridge the sim2real gap. I.e., by the time you take action, you don’t want your world to have changed by too much.
Rather than forcing “spiking” into applications for the sake of it, it’s important to take it to domains where there is a computational benefit – and I think this is one of them.
Preprint: https://arxiv.org/abs/2405.19687
See the tutorial here.
The next tutorial from UCSC’s Brain-Inspired Machine Learning class is by Dylan J. Louie, Hannah Cohen Sandler and Shatoparba Banerjee.
They show how to train an SNN for tactile sensing using the Spiking-Tactile MNIST Neuromorphic Dataset. This dataset was developed in Benjamin C.K. Tee‘s lab in NUS. It consists of handwritten digits obtained by human participants writing on a neuromorphic tactile sensor array.
For more information about the dataset, see the preprint by Hian Hian See et al. here.
We have released SpikeGPT led by Ruijie Zhu and Qihang Zhao, the largest-scale SNN training via backprop to date, and (to the best of our knowledge) the first generative language spike-based model.
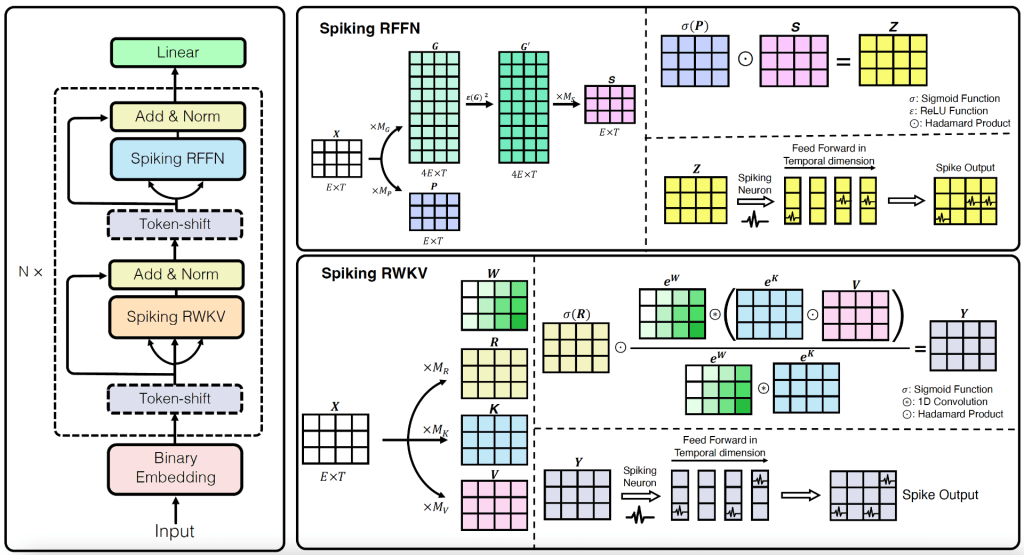
Abstract: As the size of large language models continue to scale, so does the computational resources required to run it. Spiking neural networks (SNNs) have emerged as an energy-efficient approach to deep learning that leverage sparse and event-driven activations to reduce the computational overhead associated with model inference. While they have become competitive with non-spiking models on many computer vision tasks, SNNs have also proven to be more challenging to train. As a result, their performance lags behind modern deep learning, and we are yet to see the effectiveness of SNNs in language generation. In this paper, we successfully implement `SpikeGPT’, a generative language model with pure binary, event-driven spiking activation units. We train the proposed model on three model variants: 45M, 125M and 260M parameters. To the best of our knowledge, this is 4x larger than any functional backprop-trained SNN to date. We achieve this by modifying the transformer block to replace multi-head self attention to reduce quadratic computational complexity to linear with increasing sequence length. Input tokens are instead streamed in sequentially to our attention mechanism (as with typical SNNs). Our preliminary experiments show that SpikeGPT remains competitive with non-spiking models on tested benchmarks, while maintaining 5x less energy consumption when processed on neuromorphic hardware that can leverage sparse, event-driven activations. Our code implementation is available at https://github.com/ridgerchu/SpikeGPT.
Preprint: https://arxiv.org/abs/2302.13939
Code: https://github.com/ridgerchu/SpikeGPT
BPLC + NOSO has been published, led by Seong Min Jin and Doo Seok Jeong (Jeong Lab), along with collaborators Dohun Kim and Dong Hyung Yoo.
Abstract: For mathematical completeness, we propose an error-backpropagation algorithm based on latency code (BPLC) with spiking neurons conforming to the spike–response model but allowed to spike once at most (NOSOs). BPLC is based on gradients derived without approximation unlike previous temporal code-based error-backpropagation algorithms. The latency code uses the spiking latency (period from the first input spike to spiking) as a measure of neuronal activity. To support the latency code, we introduce a minimum-latency pooling layer that passes the spike of the minimum latency only for a given patch. We also introduce a symmetric dual threshold for spiking (i) to avoid the dead neuron issue and (ii) to confine a potential distribution to the range between the symmetric thresholds. Given that the number of spikes (rather than timesteps) is the major cause of inference delay for digital neuromorphic hardware, NOSONets trained using BPLC likely reduce inference delay significantly. To identify the feasibility of BPLC + NOSO, we trained CNN-based NOSONets on Fashion-MNIST and CIFAR-10. The classification accuracy on CIFAR-10 exceeds the state-of-the-art result from an SNN of the same depth and width by approximately 2%. Additionally, the number of spikes for inference is significantly reduced (by approximately one order of magnitude), highlighting a significant reduction in inference delay.
Paper: https://link.springer.com/article/10.1007/s40747-023-00983-y
Code: https://github.com/dooseokjeong/BPLC-NOSO

We have a new a new snnTorch tutorial/notebook on training spiking neurons with varied types of recurrent spiking neurons.
This is the second tutorial in a 3-part series on regression.
Link to the tutorial here.

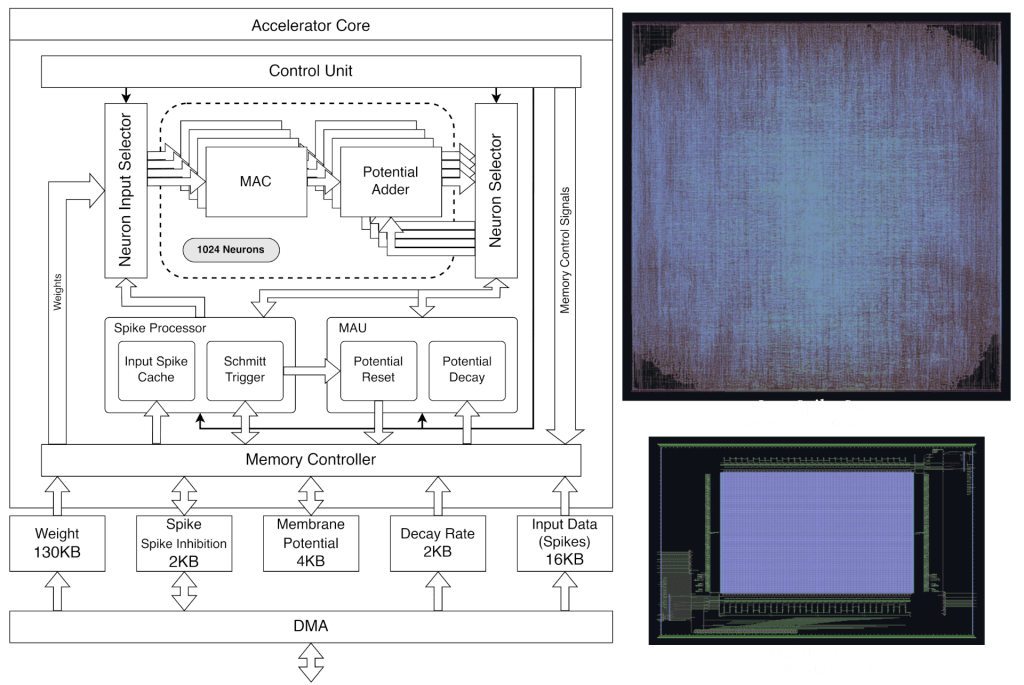
Farhad Modaresi has led the design and tape-out of a fully open-sourced spiking neural network accelerator in the Skywater 130 process. The design is based on memory macros generated using OpenRAM.
Many of the advances in deep learning this past decade can be attributed to the open-source movement where researchers have been able to reproduce and iterate upon open code bases. With the advent of open PDKs (SkyWater), EDA toolchains, and memory compilers (OpenRAM by co-author Matthew Guthaus), we hope to port rapid acceleration in hardware development to the neuromorphic community.
Check out the preprint here: https://arxiv.org/abs/2302.01015
GitHub repo with RTL you are welcome to steal: https://github.com/sfmth/OpenSpike
We have a new a new snnTorch tutorial/notebook on nonlinear regression with SNNs.
This first part will show you how to train a spiking neuron’s membrane potential to follow a given trajectory over time. Future tutorials will introduce spiking LSTM models, recurrent leaky integrator neurons, and do some more fancy regression tasks.
Link to the tutorial here.

Nonlinear Regression with SNNs
We now have snnTorch accelerated on Graphcore’s Intelligent Processing Units (IPUs), co-developed by Vincent Sun, Jason Eshraghian, along with assistance from Graphcore.
See this link for a tutorial to train SNNs on IPUs.
We have a new preprint along with code that simplifies the process of training quantized spiking neural networks in snnTorch.
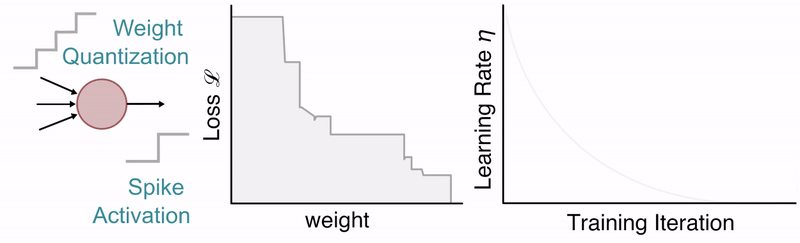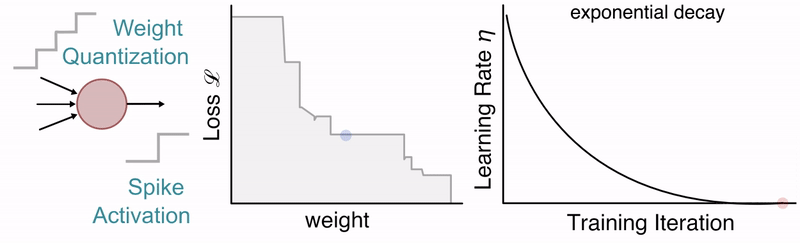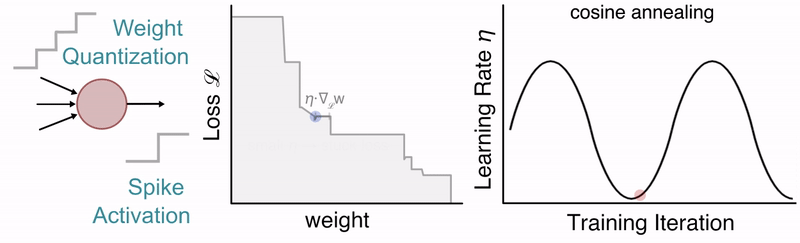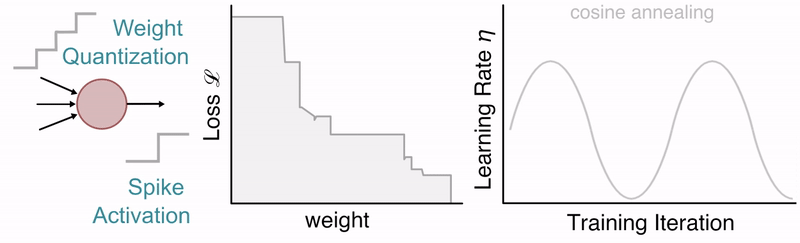
Quantization-Aware training of SNNs with periodic schedules
We propose several techniques to smooth the process of training QSNNs, one of which is the use of cosine annealing and periodic boosting, which provides the network additional opportunities to continue searching for more optimized solution spaces.
Github link to code here.
Preprint link here.
We have a new a new snnTorch tutorial/notebook on population coding.
Biologically, the average neuronal firing rate is roughly 0.1-1Hz, which is far slower than the reaction response time of animals and humans.
But if we pool together multiple neurons and count their spikes together, then it becomes possible to measure a firing rate for a population of neurons in a very short window of time.
As it turns out, population codes are also a handy trick for deep learning. Having more output neurons provides far more ‘pathways’ for errors to backprop through.
It also lets us take a more ‘parallel’ approach to training SNNs by swapping sequential steps through time for matrix-vector mults.
Here, we run through using a large pool of output neurons (instead of just the usual ~10 output neurons) to obtain decent results in 1 single simulated time-step.
Link to the tutorial here.

Population Codes in SNNs

snnTorch at PyTorch Developer Day
Check out the line up of speakers here.
How can we train biologically plausible Spiking Neural Networks with the Deep Learning hammer? Our perspective/tutorial/review aims to tackle this question. We explore how the neural code affects learning via gradient descent, the interplay between the STDP learning rule and the backpropagation-through-time algorithm, and step through using online learning with SNNs.

Computational graph of a spiking neuron
This preprint goes hand-in-hand with our recently updated snnTorch interactive tutorial series that goes from designing simple spiking neurons to training large-scale networks.
Link to the preprint here.
Link to the SNN tutorial series here.
snnTorch GitHub link here.
Our retina-controlled upper-limb prosthesis system led by Coen Arrow won the Best Live Demonstration Award at the IEEE International Conference on Electronic Circuits and Systems.
Using sparse spiking electrical signals generated by retina photoreceptor cells in real-time could potentially assist with rehabilitation, and complement EMG signals to achieving high-precision feedback on a constrained power supply.
We somehow did this whole thing remotely across three continents, with Coen Arrow at the University of Western Australia; Hancong Wu & Kia Nazarpour at the University of Edinburgh, and the University of Michigan.
Code for the retina simulator can be found here.
