
Abstract: Is it possible to learn from the future? Here, we introduce knowledge distillation through time (KDTT). In traditional knowledge distillation (KD), a reliable teacher model is used to train an error-prone student model. The difference between the teacher and student is typically model capacity; the teacher is larger in architecture. In KDTT, the teacher and student models differ in their assigned tasks. The teacher model is tasked with detecting events in sequential data, a simple task compared to the student model, which is challenged with forecasting said events in the future. Through KDTT, the student can use the ’future’ logits from a teacher model to extract temporal uncertainty. We show the efficacy of KDTT on seizure prediction, where the student forecaster achieves a 20.0% average increase in the area under the curve of the receiver operating characteristic (AUC-ROC)
Category Archives: Research
New Paper: “Optically Tunable Electrical Oscillations in Oxide-Based Memristors for Neuromorphic Computing” led by Collaborator Dr. Shimul K. Nath
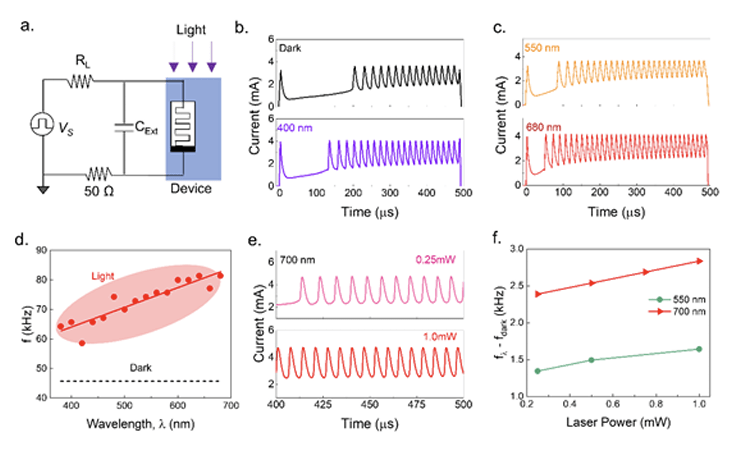
The application of hardware-based neural networks can be enhanced by integrating sensory neurons and synapses that enable direct input from external stimuli. Here, we report direct optical control of an oscillatory neuron based on volatile threshold switching in V 3 O 5. The devices exhibit electroforming-free operation with switching parameters that can be tuned by optical illumination. Using temperature-dependent electrical measurements, conductive atomic force microscopy (C-AFM), in-situ thermal imaging, and lumped element modelling, we show that the changes in switching parameters, including threshold and hold voltages, arise from overall conductivity increase of the oxide film due to the contribution of both photo-conductive and bolometric characteristics of V 3 O 5, which eventually affects the oscillation dynamics. Furthermore, our investigation reveals V 3 O 5 as a new bolometric material with a remarkable temperature coefficient of resistivity (TCR) as high as-4.6% K-1 at 423 K. We show the utility of optically tuneable device response and spiking frequency by demonstrating in-sensor reservoir computing with reduced computational effort and an optical encoding layer for spiking neural network, respectively, using a simulated array of devices. This article is protected by copyright. All rights reserved.
New Preprint: “Addressing cognitive bias in medical language models” led by Ph.D. Candidate Samuel Schmidgall
Preprint link here.
Abstract: The integration of large language models (LLMs) into the medical field has gained significant attention due to their promising accuracy in simulated clinical decision-making settings. However, clinical decision-making is more complex than simulations because physicians’ decisions are shaped by many factors, including the presence of cognitive bias. However, the degree to which LLMs are susceptible to the same cognitive biases that affect human clinicians remains unexplored. Our hypothesis posits that when LLMs are confronted with clinical questions containing cognitive biases, they will yield significantly less accurate responses compared to the same questions presented without such biases.In this study, we developed BiasMedQA, a novel benchmark for evaluating cognitive biases in LLMs applied to medical tasks. Using BiasMedQA we evaluated six LLMs, namely GPT-4, Mixtral-8x70B, GPT-3.5, PaLM-2, Llama 2 70B-chat, and the medically specialized PMC Llama 13B. We tested these models on 1,273 questions from the US Medical Licensing Exam (USMLE) Steps 1, 2, and 3, modified to replicate common clinically-relevant cognitive biases. Our analysis revealed varying effects for biases on these LLMs, with GPT-4 standing out for its resilience to bias, in contrast to Llama 2 70B-chat and PMC Llama 13B, which were disproportionately affected by cognitive bias. Our findings highlight the critical need for bias mitigation in the development of medical LLMs, pointing towards safer and more reliable applications in healthcare.
NSF MRSEC Seed Grant Awarded for the Co-Design of Next Generation Heterostructure-based Memristor for Neuromorphic Computing
New Paper: “To spike or not to spike: A digital hardware perspective on deep learning acceleration” led by Dr. Fabrizio Ottati in IEEE JETCAS
Find the paper on IEEE Xplore here.
Abstract:
As deep learning models scale, they become increasingly competitive from domains spanning from computer vision to natural language processing; however, this happens at the expense of efficiency since they require increasingly more memory and computing power. The power efficiency of the biological brain outperforms any large-scale deep learning (DL) model; thus, neuromorphic computing tries to mimic the brain operations, such as spike-based information processing, to improve the efficiency of DL models. Despite the benefits of the brain, such as efficient information transmission, dense neuronal interconnects, and the co-location of computation and memory, the available biological substrate has severely constrained the evolution of biological brains. Electronic hardware does not have the same constraints; therefore, while modeling spiking neural networks (SNNs) might uncover one piece of the puzzle, the design of efficient hardware backends for SNNs needs further investigation, potentially taking inspiration from the available work done on the artificial neural networks (ANNs) side. As such, when is it wise to look at the brain while designing new hardware, and when should it be ignored? To answer this question, we quantitatively compare the digital hardware acceleration techniques and platforms of ANNs and SNNs. As a result, we provide the following insights: (i) ANNs currently process static data more efficiently, (ii) applications targeting data produced by neuromorphic sensors, such as event-based cameras and silicon cochleas, need more investigation since the behavior of these sensors might naturally fit the SNN paradigm, and (iii) hybrid approaches combining SNNs and ANNs might lead to the best solutions and should be investigated further at the hardware level, accounting for both efficiency and loss optimization.
New Paper: “Capturing the Pulse: A State-of-the-Art Review on Camera-Based Jugular Vein Assessment” led by Ph.D. Candidate Coen Arrow in Biomedical Optics Express
See the full paper here.
Abstract
Heart failure is associated with a rehospitalisation rate of up to 50% within six months. Elevated central venous pressure may serve as an early warning sign. While invasive procedures are used to measure central venous pressure for guiding treatment in hospital, this becomes impractical upon discharge. A non-invasive estimation technique exists, where the clinician visually inspects the pulsation of the jugular veins in the neck, but it is less reliable due to human limitations. Video and signal processing technologies may offer a high-fidelity alternative. This state-of-the-art review analyses existing literature on camera-based methods for jugular vein assessment. We summarize key design considerations and suggest avenues for future research. Our review highlights the neck as a rich imaging target beyond the jugular veins, capturing comprehensive cardiac signals, and outlines factors affecting signal quality and measurement accuracy. Addressing an often quoted limitation in the field, we also propose minimum reporting standards for future studies.
Brain-Inspired Machine Learning at UCSC: Class Tape-out Success
This quarter, I introduced Brain-Inspired Machine Learning as a course to University of California, Santa Cruz. And while machine learning is cool and all, it’s only as good as the hardware it runs on.
31 students & first time chip designers all took the lead on building DRC/LVS clean neuromorphic circuits. Students came from grad & undergrad backgrounds across various corners of the university. ECE, CSE, Math, Computational Media, Bioengineering, Psychology, etc. Many had never even taken an ECE 101 class, and started learning from scratch 2 weeks ago.
Their designs are now all being manufactured together in the Sky130 Process. Each design is compiled onto the same piece of silicon with TinyTapeout, thanks to Matt Venn and Uri Shaked.
We spent Friday night grinding in my lab while blaring metalcore tunes. All students managed to clear all checks. The final designs do a heap of cool things like accelerate sparse matrix-multiplies, event denoising, to simulating reservoir networks. I naturally had to squeeze in a Hodgkin-Huxley neuron in the 6 hours before the deadline (pictured).
Not sure if it’s the cost of living, or the mountain lions on campus, but damn. UCSC students have some serious grit.

New Paper: “Training spiking neural networks using lessons from deep learning” in the Proceedings of the IEEE
My baby was finally accepted for publication. Available open-access on IEEE Xplore.
Telluride Workshop: Open Source Neuromorphic Hardware, Software and Wetware
Prof. Jason Eshraghian & Dr. Peng Zhou were topic area leaders at the Telluride Neuromorphic Engineering & Cognition Workshop. Tasks addressed included:
-
porting open silicon (hardware) to neuromorphic engineering,
-
linking in-vitro neural networks (wetware) to neuromorphic computing, and
-
modelling and training those with spiking neural networks using neuromorphic software.
A project highlight includes the development of the Neuromorphic Intermediate Representation (NIR), an intermediate representation to translate various neuromorphic and physics-driven models that are based on continuous time ODEs into different formats. This makes it much easier to deploy models trained in one library to map to a large variety of backends.

Ruijie Zhu and Prof. Jason Eshraghian Present Invited Talk “Scaling up SNNs with SpikeGPT” at the Intel Neuromorphic Research Centre
Abstract: If we had a dollar for every time we heard “It will never scale!”, then neuromorphic engineers would be billionaires. This presentation will be centered on SpikeGPT, the first large-scale language model (LLM) using spiking neural nets (SNNs), and possibly the largest SNN that has been trained using error backpropagation.
The need for lightweight language models is more pressing than ever, especially now that we are becoming increasingly reliant on them from word processors and search engines, to code troubleshooting and academic grant writing. Our dependence on a single LLM means that every user is potentially pooling sensitive data into a singular database, which leads to significant security risks if breached.
SpikeGPT was built to move towards addressing the privacy and energy consumption challenges we presently run into using Transformer blocks. Our approach decomposes self-attention down into a recurrent form that is compatible with spiking neurons, along with dynamical weight matrices where the dynamics are learnable, rather than the parameters as with conventional deep learning.
We will provide an overview of what SpikeGPT does, how it works, and what it took to train it successfully. We will also provide a demo on how users can download pre-trained models available on HuggingFace so that listeners are able to experiment with them.
Link to the talk can be found here.
New Preprint: Brain-inspired learning in artificial neural networks: A Review led by Ph.D. Candidate Samuel Schmidgall
Abstract: Artificial neural networks (ANNs) have emerged as an essential tool in machine learning, achieving remarkable success across diverse domains, including image and speech generation, game playing, and robotics. However, there exist fundamental differences between ANNs’ operating mechanisms and those of the biological brain, particularly concerning learning processes. This paper presents a comprehensive review of current brain-inspired learning representations in artificial neural networks. We investigate the integration of more biologically plausible mechanisms, such as synaptic plasticity, to enhance these networks’ capabilities. Moreover, we delve into the potential advantages and challenges accompanying this approach. Ultimately, we pinpoint promising avenues for future research in this rapidly advancing field, which could bring us closer to understanding the essence of intelligence.
Link to the preprint here.

Preprint Update: Training Spiking Neural Networks Using Lessons from Deep Learning
We submitted this extensive (and opinionated) guide to training spiking neural networks to the Proceedings of the IEEE 18 months ago. During this time, the preprint has reached 100+ citations, snnTorch has cracked 80,000 downloads, and it has helped numerous people enter the field of neuromorphic computing… and much of the content that was true 18 months ago has significantly changed.

While we continue to wait for the peer review process to do its thing, I’ve taken the liberty to revamp the preprint to reflect the rapidly changing world of training and using SNNs.
The latest version includes “Practical Notes” with black magic tricks that have helped us improve the performance of SNNs, code-snippets that reduce verbose explanations, and a fresh account of some of the latest going-ons in the neuroscience-inspired deep learning world..
Thank you to Gregor Lenz, Xinxin Wang and Max Ward for working through this >50 page monster.
Preprint link here.
IEEE Transactions on Circuits and Systems Darlington Best Paper Award
The paper titled “How to Build a Memristive Integrate-and-Fire Neuron for Spiking Neuronal Signal Generation” has been awarded the 2023 IEEE Transaction on Circuits and Systems Darlington Best Paper Award. This paper was led by Prof. Sung-Mo Kang, Prof. Jason Eshraghian and Prof. Leon O. Chua in a collaboration spanning UC Santa Cruz, UC Berkeley, University of Michigan, TU Dresden, and Syungkyunkwan University.
The Darlington Best Paper Award annually recognizes one paper that bridges the gap between theory and practice published in the IEEE Transactions on Circuits and Systems and was presented to authors at the 2023 IEEE International Symposium on Circuits and Systems in Monterey, California.

See the announcement here.
The paper is available via IEEE.
New Preprint: PowerGAN: A Machine Learning Approach for Power Side-Channel Attack on Compute-in-Memory Accelerators led by Ph.D. Candidate Ziyu Wang and Prof. Wei D. Lu
Led by Ziyu Wang and Prof. Wei D. Lu (University of Michigan).
Abstract: Analog compute-in-memory (CIM) accelerators are becoming increasingly popular for deep neural network (DNN) inference due to their energy efficiency and in-situ vector-matrix multiplication (VMM) capabilities. However, as the use of DNNs expands, protecting user input privacy has become increasingly important. In this paper, we identify a security vulnerability wherein an adversary can reconstruct the user’s private input data from a power side-channel attack, under proper data acquisition and pre-processing, even without knowledge of the DNN model. We further demonstrate a machine learning-based attack approach using a generative adversarial network (GAN) to enhance the reconstruction. Our results show that the attack methodology is effective in reconstructing user inputs from analog CIM accelerator power leakage, even when at large noise levels and countermeasures are applied. Specifically, we demonstrate the efficacy of our approach on the U-Net for brain tumor detection in magnetic resonance imaging (MRI) medical images, with a noise-level of 20% standard deviation of the maximum power signal value. Our study highlights a significant security vulnerability in analog CIM accelerators and proposes an effective attack methodology using a GAN to breach user privacy.
Preprint: https://arxiv.org/abs/2304.11056
New Preprint: NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Led by Jason Yik, Vijay Janapa Reddi (Harvard University), and Charlotte Frenkel (TU Delft), the NeuroBench project aims to drive progress in neuromorphic computing by defining benchmarks for neuromorphic algorithms and systems.
Abstract: The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit this http URL for the latest updates on the benchmark tasks and metrics.
Preprint: https://arxiv.org/abs/2304.04640
Website: https://neurobench.ai/
New Paper: “Side-channel attack analysis on in-memory computing architectures” led by Ph.D. candidate Ziyu Wang from the Lu Group published in IEEE Trans. Emerging Topics in Computing
“Side-channel attack analysis on in-memory computing architectures” has been published, led by Ziyu Wang and Prof. Wei Lu (Lu Group), along with collaborators Fan-Hsuan Meng and Yongmo Park.
Abstract—In-memory computing (IMC) systems have great potential for accelerating data-intensive tasks such as deep neural networks (DNNs). As DNN models are generally highly proprietary, the neural network architectures become valuable targets for attacks. In IMC systems, since the whole model is mapped on chip and weight memory read can be restricted, the system acts as a ”black box” for customers. However, the localized and stationary weight and data patterns may subject IMC systems to other attacks. In this paper, we propose a side-channel attack methodology on IMC architectures. We show that it is possible to extract model architectural information from power trace measurements without any prior knowledge of the neural network. We first developed a simulation framework that can emulate the dynamic power traces of the IMC macros. We then performed side-channel attacks to extract information such as the stored layer type, layer sequence, output channel/feature size and convolution kernel size from power traces of the IMC macros. Based on the extracted information, full networks can potentially be reconstructed without any knowledge of the neural network. Finally, we discuss potential countermeasures for building IMC systems that offer resistance to these model extraction attack.

New Preprint: “SpikeGPT: Generative Pre-Trained Language Model with Spiking Neural Networks” led by incoming Ph.D. candidate Ruijie Zhu
We have released SpikeGPT led by Ruijie Zhu and Qihang Zhao, the largest-scale SNN training via backprop to date, and (to the best of our knowledge) the first generative language spike-based model.
Abstract: As the size of large language models continue to scale, so does the computational resources required to run it. Spiking neural networks (SNNs) have emerged as an energy-efficient approach to deep learning that leverage sparse and event-driven activations to reduce the computational overhead associated with model inference. While they have become competitive with non-spiking models on many computer vision tasks, SNNs have also proven to be more challenging to train. As a result, their performance lags behind modern deep learning, and we are yet to see the effectiveness of SNNs in language generation. In this paper, we successfully implement `SpikeGPT’, a generative language model with pure binary, event-driven spiking activation units. We train the proposed model on three model variants: 45M, 125M and 260M parameters. To the best of our knowledge, this is 4x larger than any functional backprop-trained SNN to date. We achieve this by modifying the transformer block to replace multi-head self attention to reduce quadratic computational complexity to linear with increasing sequence length. Input tokens are instead streamed in sequentially to our attention mechanism (as with typical SNNs). Our preliminary experiments show that SpikeGPT remains competitive with non-spiking models on tested benchmarks, while maintaining 5x less energy consumption when processed on neuromorphic hardware that can leverage sparse, event-driven activations. Our code implementation is available at https://github.com/ridgerchu/SpikeGPT.
Preprint: https://arxiv.org/abs/2302.13939
Code: https://github.com/ridgerchu/SpikeGPT
New Paper: “BPLC + NOSO: Backpropagation of errors based on latency code with neurons that only spike once at most” led by Ph.D. candidate Seong Min Jin published in Complex Intelligent Systems
BPLC + NOSO has been published, led by Seong Min Jin and Doo Seok Jeong (Jeong Lab), along with collaborators Dohun Kim and Dong Hyung Yoo.
Abstract: For mathematical completeness, we propose an error-backpropagation algorithm based on latency code (BPLC) with spiking neurons conforming to the spike–response model but allowed to spike once at most (NOSOs). BPLC is based on gradients derived without approximation unlike previous temporal code-based error-backpropagation algorithms. The latency code uses the spiking latency (period from the first input spike to spiking) as a measure of neuronal activity. To support the latency code, we introduce a minimum-latency pooling layer that passes the spike of the minimum latency only for a given patch. We also introduce a symmetric dual threshold for spiking (i) to avoid the dead neuron issue and (ii) to confine a potential distribution to the range between the symmetric thresholds. Given that the number of spikes (rather than timesteps) is the major cause of inference delay for digital neuromorphic hardware, NOSONets trained using BPLC likely reduce inference delay significantly. To identify the feasibility of BPLC + NOSO, we trained CNN-based NOSONets on Fashion-MNIST and CIFAR-10. The classification accuracy on CIFAR-10 exceeds the state-of-the-art result from an SNN of the same depth and width by approximately 2%. Additionally, the number of spikes for inference is significantly reduced (by approximately one order of magnitude), highlighting a significant reduction in inference delay.
Paper: https://link.springer.com/article/10.1007/s40747-023-00983-y
Code: https://github.com/dooseokjeong/BPLC-NOSO
New snnTorch Tutorial: Regression with Recurrent Spiking Neurons (Part II)
We have a new a new snnTorch tutorial/notebook on training spiking neurons with varied types of recurrent spiking neurons.
This is the second tutorial in a 3-part series on regression.
Link to the tutorial here.

New Paper: “Neuromorphic Deep Spiking Neural Networks for Seizure Detection” led by Ph.D. Candidate Yikai Yang Published in Neuromorphic Computing and Engineering
Abstract: The vast majority of studies that process and analyze neural signals are conducted on cloud computing resources, which is often necessary for the demanding requirements of Deep Neural Network (DNN) workloads. However, applications such as epileptic seizure detection stand to benefit from edge devices that can securely analyze sensitive medical data in real-time and personalised manner. In this work, we propose a novel neuromorphic computing approach to seizure detection using a surrogate gradient-based deep Spiking Neural Network (SNN), which consists of a novel Spiking ConvLSTM unit (SPCLU). We have trained, validated, and rigorously tested the proposed SNN model across three publicly accessible datasets, including Boston Children’s Hospital–MIT (CHB-MIT) dataset from the U.S., and the Freiburg (FB) and EPILEPSIAE intracranial EEG (iEEG) datasets from Germany. The average leave-one-out cross-validation AUC score for FB, CHB-MIT, and EPILEPSIAE datasets can reach 92.7%, 89.0%, and 81.1%, respectively, while the computational overhead and energy consumption are significantly reduced when compared to alternative state-of-the-art models, showing the potential for building an accurate hardware-friendly, low-power neuromorphic system. This is the first feasibility study using a deep Spiking Neural Network for seizure detection on several reliable public datasets.
Read more here.